前言
博客里的内容越来越多之后,为了能够更快地获取到想要的数据,全文搜索功能成为必要功能。于是我开始尝试vitepress官方推荐的一些搜索实现。本来是使用 algolia 来做搜索,但是当我申请好了key,配置好了爬虫,在 algolia 的控制台也能看到爬取到的页面记录了,但是在页面上怎么也搜索不到内容。我尝试多种方式来解问题,如 lang 配置问题;重新修改search api key,都不能解决问题。而官方对接入的免费的文档搜索,并不提供技术支持。在调研了一圈没有解决办法后,只能换另外一种搜索的方式,因为之前使用 vitepress 自带的 local 搜索,效果并不理想,那就再来看看能不能在 local 搜索的基础上提高搜索的精准度。
vitepress 配置搜索
修改vite的配置文件增加以下的代码,就可以在页面开启搜索入口。
// docs/.vitepress/config.ts
import { defineConfig } from 'vitepress'
// 自定义分词函数
function customTokenizer(text) {
// 去除空格,每个字分词
return Array.from(new Intl.Segmenter('cn', { granularity: 'word' }).segment(text.replace(/ /g, ''))).map(item => item.segment)
}
export default defineConfig({
themeConfig: {
search: {
provider: 'local',
options: {
locales: { /** 省略代码... */ },
miniSearch: {
options: {
tokenize: customTokenizer // 使用自定义分词器
},
},
},
}
},
})配置完之后就会出现下面的搜索框了。然后代码里高亮的两行就是对中文分词的优化了。也可以点击上面的搜索体验一下。 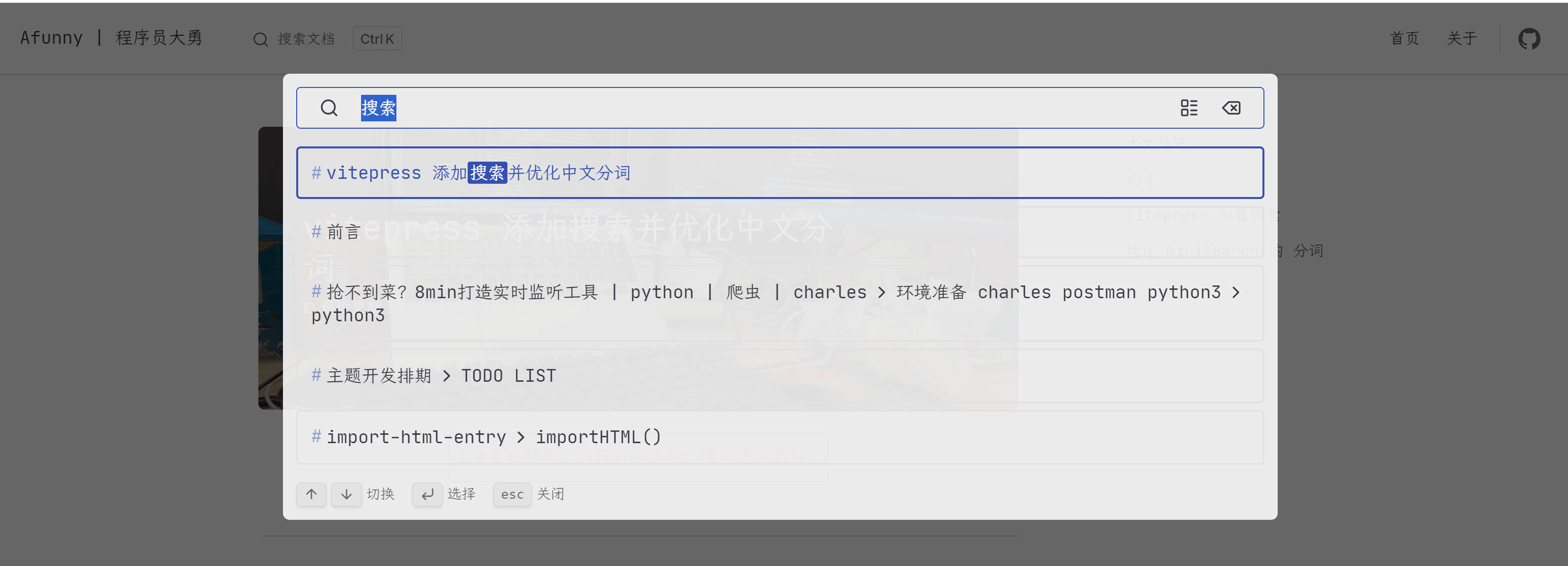
修改以上的配置页面基本就可以正常搜索了。接下来分析下对中文分词的优化。
优化 minisearch 的分词
vitepress 默认支持的搜索使用的是 miniSearch,但是他对中文的支持并不友好,比如我在搜索关键词如“网盘”的时候,搜索不出来任何结果。但是它支持传入自定义的分词方法miniSearch.options.tokenize,这就给了我们优化的空间。
customTokenizer 是传入的自定义的分词方法,这里使用的是js原生支持的API Intl.Segmenter来做分词。vitepress 的分词在编译时执行一次,然后生成分词好的索引文件,是在nodejs的环境里使用的。中文分析越详细,索引文件就越大,用户加载时就会越慢,所以要在加载速度和搜索精准度上做好取舍。目前这个网站的索引文件约为55k,而且是在点击搜索框之后才会加载,也不会影响首屏加载。所以目前都还挺好。
miniSearch: {
options: {
tokenize: customTokenizer // 传入自定义分词器
},
}
function customTokenizer(text) {
// 去除空格,每个字分词。返回字符串的数组
return Array.from(new Intl.Segmenter('cn', { granularity: 'word' }).segment(text.replace(/ /g, ''))).map(item => item.segment)
}测试Intl.Segmenter分词效果
不得不祭出经典测试用例, 分词效果还不错,满足日常需求。
console.table(Array.from(new Intl.Segmenter('cn', { granularity: 'word' }).segment('工信处女干事每月经过下属科室都要亲口交代 24 口交换机等技术性器件的安装工作')))